
C# 기반 프로그램에서 웹페이지 내용을 얻고 싶을 때, 단순한 웹페이지라면 HttpClient를 이용하면 간단하게 취득할 수 있습니다.
하지만 모던 웹 환경은 Javascript와 HTML이 긴밀하게 엮여서 컨텐츠를 생성하기 때문에, 단순히 특정 주소의 HTML 파일만 취득해서는 내가 원하는 내용이 들어있지 않을 수 있습니다.
간단히 설명하자면, HTML 안에 명시되어있는 각종 Javascript 파일과 CSS 파일들도 불러와서 실행을 해야 완전한 웹페이지가 만들어지는데요, 이 과정은 우리가 크롬 같은 웹브라우저에서 어떤 사이트에 들어갈 때 페이지가 다 불러와질때까지 기다리는 과정과 같습니다.
아래 스크린샷은 엣지 브라우저에서 네이버에 들어갔을 때의 과정을 보여줍니다. 약 2.5초동안 HTML, Javascript, CSS를 불러오고 동적으로 컨텐츠를 생성할 뿐만 아니라 수많은 이미지와 리소스를 다운로드하고 화면에 표시하게 됩니다.
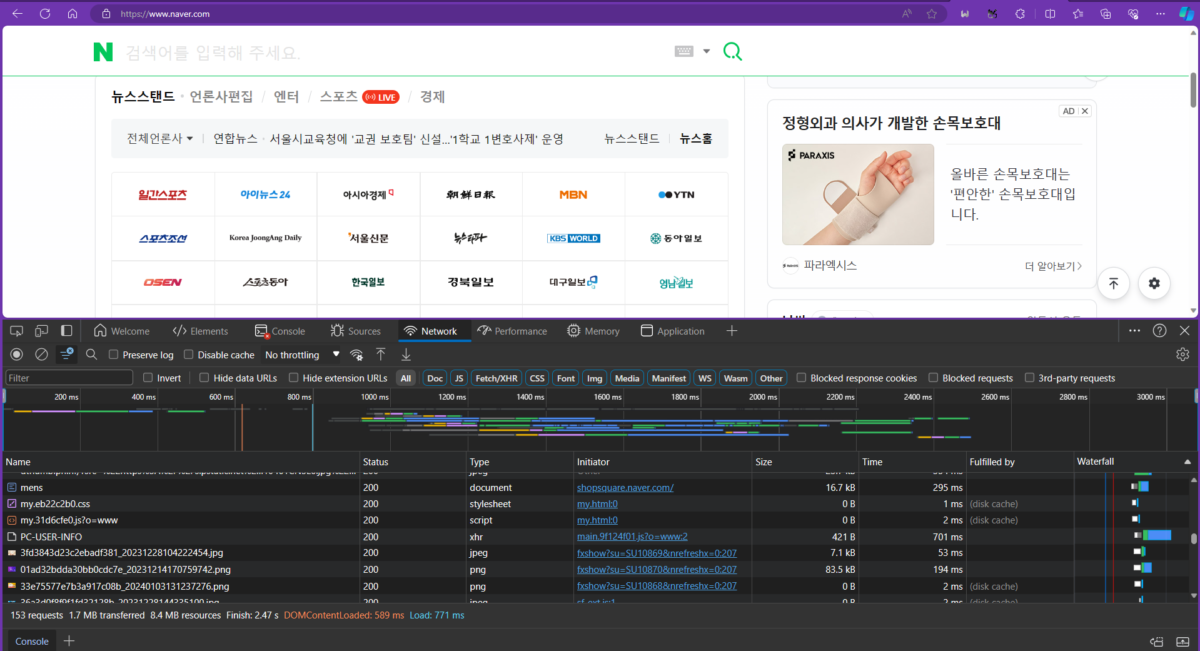
그렇다는 말은 우리가 만들 프로그램에서 웹페이지를 문제없이 크롤링하기 위해서는 사실 이런 과정까지 처리해줘야 한다는건데요, 생각했던것보다 일이 굉장히 커지지 않나요? 거의 웹브라우저를 하나 만들어야 할 지경이네요.
사실 그래서 웹 크롤링 전문 라이브러리들이 따로 있습니다. Python에선 한때 BeautifulSoup이 많이 쓰였고, 지금은 Scrapy가 대중적인 픽이죠. Javascript에선 PhantomJS가 무난한 선택지였지만 개발이 중단된 이후로는 Puppeteer가 많이들 쓰이고 있습니다.
그럼 C#은 어떨까요? 한때 PhantomJS을 .NET으로 포팅한 라이브러리가 많이 쓰였지만 개발이 멈춘 이후로는 Selenium 정도가 남아있는 선택지였습니다. 하지만 Selenium은 브라우저별로 ChromeDriver 같은 드라이버 프로그램을 통해 간접적으로 웹브라우징을 지원하기 때문에, 종종 내부적인 오류가 생겨서 귀찮아지는 일이 있습니다.
예를 들어 드라이버로 ChromeDriver를 선택했으면 사용자의 컴퓨터에 구글 크롬이 꼭 설치되어 있어야 합니다. 그리고 ChromeDriver와 설치된 크롬의 버전의 차이가 많이 나면 둘이 연동이 되지 않기 때문에 양쪽 다 최신 버전을 유지해주거나 유지하지 말아야 합니다. 이것 때문에 사용자 환경에서 지속적으로 이용하는 환경이라면 꽤 귀찮은 상황이 자주 발생합니다.
그래서 저는 PuppeteerSharp라는 라이브러리를 추천합니다. 위에서 언급했던 Puppeteer를 .NET으로 포팅한 라이브러리인데요, 기본적으로는 웹테스트 자동화 도구로써 만들어졌지만 아래와 같은 특징 때문에 웹 크롤링에도 적합합니다.
- 아예 웹브라우저(Chromium, Firefox 등)를 로컬에 독립적으로 다운로드받아서 실행함
- 특정 URL에 접속하고, 컨텐츠들이 모두 로드된 이후의 HTML 소스 코드를 얻을 수 있음
- 설치법과 사용법이 간단함
다만 라이브러리를 기동할때 이용하는 브라우저의 버전은 라이브러리의 버전에 맞물려있기 때문에, 유튜브처럼 항상 최신버전의 브라우저에서 접속하는 걸 강제하는 사이트를 크롤링 하고싶은 경우에는 라이브러리를 지속적으로 업데이트 해줄 필요는 있습니다. (일단 제가 알아본 바로는 그렇습니다)
아무튼 서론은 여기까지 하고, 예시 코드를 설명할게요. 전체 프로젝트는 [여기]에서도 받을 수 있습니다.
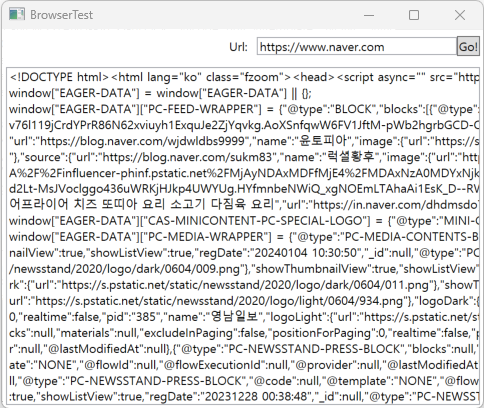
제가 만들 예제 프로그램은 WPF, .NET 8.0 기반의 GUI 프로그램으로, 아래와 같이 URL을 입력하고 Go! 버튼을 누르면 아래에 있는 TextBox에 페이지 내용을 뿌려주는 구조를 갖고 있습니다.
Visual Studio에서 새 WPF 앱을 생성한 다음에, 프로젝트의 Nuget 패키지 관리 화면을 열어서 PuppeteerSharp 패키지를 설치해주세요.
그리고 아래 코드를 참고하여 MainWindow.xaml에 각종 GUI 요소를 추가해주세요.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
<Window x:Class="browserTest.MainWindow" xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation" xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml" xmlns:d="http://schemas.microsoft.com/expression/blend/2008" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:local="clr-namespace:browserTest" mc:Ignorable="d" Title="BrowserTest" Width="400" Height="300" MinWidth="400" MinHeight="300"> <Grid> <DockPanel> <Grid DockPanel.Dock="Top"> <StackPanel Orientation="Horizontal" HorizontalAlignment="Right" Margin="4"> <Label Content="Url: " VerticalAlignment="Center"/> <TextBox Name="tbUrl" Text="https://www.google.com" Width="200" TextWrapping="Wrap" VerticalAlignment="Center"/> <Button Name="btNavigate" Click="btNavigate_Click" Content="Go!" VerticalAlignment="Center"/> </StackPanel> </Grid> <TextBox Name="tbPageRaw" Text="" Margin="4"/> </DockPanel> </Grid> </Window> |
MainWindow.xaml.cs의 내용은 아래와 같습니다. 다른건 그대로 복붙하면 되는데, MainWindow()의 내용은 InitializeComponent() 다음에 InitWebBrowser()만 추가하면 되니까 참고해주세요.
그리고 프로그램이 종료되는 시점에 반드시 browser 객체의 dispose()를 호출하여 chrome 프로세스를 종료해줘야 합니다. 그러지 않으면 앱이 종료되어도 브라우저는 메모리에 계속 남게 됩니다. 아래 코드에선 Window의 Closing 이벤트 안에서 객체를 해제해주지만, 실제론 몇 가지 안전장치를 더 달아주는게 좋습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
using PuppeteerSharp; using System.Windows; using Page = PuppeteerSharp.Page; namespace browserTest { /// <summary> /// Interaction logic for MainWindow.xaml /// </summary> public partial class MainWindow : Window { private Browser? browser; private async Task<Browser> InitBrowser() { // Since PuppeteerSharp v11.0.0, BrowserFetcher.DefaultChromiumRevision is obsolete. // Use PuppeteerSharp.BrowserData.Chrome.DefaultBuildId instead. // DefaultBuildId may be updated with Nuget packge update of PuppeteerSharp. await new BrowserFetcher().DownloadAsync(PuppeteerSharp.BrowserData.Chrome.DefaultBuildId); var _browser = await Puppeteer.LaunchAsync(new LaunchOptions { Headless = true, Args = new[] { "--js-flags=\"--max-old-space-size=128\"" // Limits memory usage to 128MB }, }); return (Browser)_browser; // Cast IBrowser to Browser } private Page? webPage; public MainWindow() { InitializeComponent(); InitWebBrowser(); } private void InitWebBrowser() { var browserTask = Task.Run(InitBrowser); browser = browserTask.GetAwaiter().GetResult(); var pageTask = Task.Run(async () => await browser.NewPageAsync()); webPage = (Page)pageTask.GetAwaiter().GetResult(); // Cast IPage to Page webPage.DefaultTimeout = 0; } private async Task<string> RequestNavigate(string url, Page page) { await page.GoToAsync(url, WaitUntilNavigation.Networkidle2); var content = await page.GetContentAsync(); return content; } private void Navigate(string url, Page page) { string content = string.Empty; try { var navigateTask = Task.Run(async () => await RequestNavigate(url, page)); content = navigateTask.GetAwaiter().GetResult(); } catch (Exception ex) { content = ex.Message; } tbPageRaw.Text = content; } private void btNavigate_Click(object sender, RoutedEventArgs e) { Navigate(tbUrl.Text, webPage); } private void Window_Closing(object sender, System.ComponentModel.CancelEventArgs e) { // Close browser webPage?.Dispose(); browser?.Dispose(); } } } |
사용하기 편하라고 일단 await를 이용해 blocking 방식으로 구현해뒀지만, 필요에 따라선 코드를 수정해서 얼마든지 비동기 방식으로 구현하실 수 있습니다.
동작 코드는 크게 준비 단계와 활용 단계로 나눌 수 있는데요, 준비 단계는 InitBrowser(), InitWebBrowser(), 활용 단계는 Navigate()와 RequestNavigate(), 그리고 btNavigate_Click()에 해당합니다.
보통 생성자 같이 프로그램이나 클래스가 최초 & 단일로 수행하는 영역 안에서 준비단계에 해당하는 메소드를 호출하면 됩니다.
각 단계에서 이름이 비슷한 메소드들이 있는 이유는 PuppeteerSharp에서 제공하는 기능들이 기본적으로 비동기 방식이기 때문에, 동기방식으로 간단히 사용하려면 await와 Task로 이들을 감싸줘야 해서 입니다.
다른 건 그냥 제 코드를 그대로 이용하시면 될거구요, btNavigate_Click() 안에서 Navigate()를 호출했듯이 실제로 브라우징을 실행해줄 UI가 동작할때 Navigate()가 실행되도록 본인의 프로그램에서 작업해주면 됩니다.
그리고 HTML을 긁어온 후에 진행할 세부적인 작업은 RequestNavigate 안에서 작업해주면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 |
private async Task<string> RequestNavigate(string url, Page page) { await page.GoToAsync(url, WaitUntilNavigation.Networkidle2); var content = await page.GetContentAsync(); // 여기에서 content에 담겨있는 HTML 코드를 처리 // HTML 처리는 HtmlAgilityPack이나 AngleSharp 라이브러리를 쓰는걸 추천 return content; } |
참고로 주석에 적었듯이 HtmlAgilityPack 같은 라이브러리를 쓰면 아래와 같이 원하는 HTML element의 내용을 쉽게 가져올 수 있습니다. 만약 찾는 element에 명시적인 id 속성이 있다면 some-div-id라고 적힌 부분을 실제 id 속성으로 교체하면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
var doc = new HtmlDocument(); doc.LoadHtml(content); string divText = string.Empty; try { var pathElement = doc.GetElementbyId("some-div-id"); divText = pathElement.InnerText.Trim(); } catch (Exception e) { Console.Error.WriteLine(e); } return divText; |
브라우저 객체(크롬 프로세스)의 종료에 관해 팁을 드리자면, 지금의 예제 코드에선 프로그램이 정상적으로 종료될때만 크롬 프로세스도 종료됩니다. 하지만 디버깅 모드로 실행한 상태에서 디버깅 종료를 통해 프로그램을 끝내거나, 오류 등으로 인해 강제 종료가 되었을 때는 객체 해제 코드가 실행되지 못하기 떄문에 크롬 프로세스도 좀비 상태로 남아있게 됩니다. 이건 본인이 직접 방법을 찾아서 처리를 해야하니 주의해주세요.
귀띔해드리자면, 제가 사용했던 방법은 아래와 같습니다.
- PuppeterSharp를 실행하는 프로그램(이하 부모 프로세스)에서 감시용 프로그램을 하나 실행한다.
- 감시 프로그램은 백그라운드에서 지속적으로 부모 프로세스의 상태를 확인한다.
- 만약 부모 프로세스가 종료되어 사라졌다면, 자신을 제외한 부모의 자식 프로세스들을 모두 죽인다.
- 감시 프로그램 자신도 종료한다.
자세한 코드는 https://github.com/sappho192/WatchDogDotNet 에서 확인할 수 있어요.
그 외의 방법은 StackOverflow[예시]라던가 구글에서 찾아보시기 바랍니다.
지금까지 PuppteerSharp로 C#에서 쉽게 웹페이지를 크롤링 하는 방법에 대해 설명드렸습니다.
다들 Python이나 Javascript(NodeJS)로 크롤링을 하는지, C#에서 하는 방법에 관한 글은 몇 년째 거의 없더라구요. 사실 PuppeteerSharp로 크롤링 하는 방법은 영문 웹에도 잘 안 나와있어서 이참에 글을 남기게 되었습니다. C# 정말 좋은 언어인데 ㅠㅠ 왤케 인기가 없을까요…
좋은 글 잘보고 갑니다. c# 인기가 더 많아졌으면 좋겠어요 ㅠㅠ
좋은 글 잘 봤습니다. 근데 링크가 잘못 되어 있는 거 같아요.
https://github.com/sappho192/dotnet-crawler-example 이 맞지 않을까 합니다.